
PROGRAMMING: SDMV (Single Draw Multiple Viewport) Instanced Cubemap Rendering
Combining Basic Instanced Draws with Vertex Shader Output Layer Functionality for Fun and Profit

Introduction
Rendering real-time cubemaps, especially in a per-frame context, is a tricky business. There are a number of reasons why we would want to do this; the technique which immediately springs to mind is computing 360-degree shadows for omni-directional point lights (which involves rendering to depth), but there are also real-time reflection probes to consider (which involves rendering in color). I’m sure there are other applications I’m forgetting. The common trend among all of these, however, is the necessity to capture the scene in all directions, and due to the field-of-view limitations of perspective-projected imaging, this necessitates capturing the entire scene six times in order to get all the information we need. Each time we render the scene, we use different camera angles respectively pointed along all three dimensional axes (X, Y, and Z) and in both relative directions for each of these (positive and negative), making six camera angles in total.
The traditional problem with this requirement is a logistical one in terms graphics API functionality. Historically, we could only render to one fixed viewport at a time, requiring us to perform six entirely separate draw calls and update some piece of the global pipeline state between each one (i.e. resetting the camera view and projection matrix uniform variable). Needless to say, invoking a draw call and rendering the same scene six whole times to capture what is effectively one image is suboptimal. For obvious performance reasons, we would like to be able to perform this technique in a single draw.
Historical Solutions
Modern APIs offer multi-viewport rendering as a core specification feature (though you need to query for its availability on your GPU), so now we can bind all six required viewports for rendering at once, but even this on its own is not sufficient. Graphics pipeline rasterization is still going to require what is effectively six copies of the scene geometry to pass through primitive assembly to make sure that all six viewport render targets are effectively rasterized. We can generate these copies through simple instancing, but the vertex shader does not (by default) give us the control to determine which instance vertices go to which viewport (or which layer/face, in case we have bound a cubemap image for rendering directly), so we need something else.
The geometry shader is a well-known solution to this problem, though it comes at a price. In GLSL, the geometry shader stage allows the use of built-in outputs gl_ViewportIndex and gl_Layer to direct our output vertices to the desired viewport or cubemap face, respectively. Additionally, we can use EmitVertex() to directly create the necessary new vertices for the six copies of the scene directly in the shader, so no instancing is required. It sounds perfect, but as any programmer will tell you, there is no such thing as a free lunch. Geometry shaders and their inner workings within the graphics pipeline are notoriously inefficient, so much so that employing them for this purpose will almost never grant us the performance wins we desire by reducing the draw call count in the first place, and in fact can often result in a performance loss. At best, it is the sort of thing where you need to profile on a GPU-by-GPU basis to see if it is even worth using geometry shaders at all. In many cases for a shipping application intended to run on as wide a range of hardware as possible, we are right back at square one.
A Modern Approach
“There’s got to be a better way!”
Well, a Vulkan extension that has been promoted to the version 1.2 core specification since its introduction comes to the rescue! VK_EXT_shader_viewport_index_layer allows us to use the aforementioned gl_ViewportIndex and gl_Layer built-in outputs of GLSL in the vertex (and tessellation) shader stage as well as in geometry shaders! Simply put, if we combine this functionality with simple instanced rendering of the scene geometry to generate vertex shader invocations for all six viewports, we can then use gl_InstanceID within the vertex shader to ensure that each vertex is sent to the instance’s corresponding viewport!
(NOTE: If Vulkan isn’t your thing, DirectX12 also supports this functionality in the form of D3D12_FEATURE_DATA_D3D12_OPTIONS::VPAndRTArrayIndexFromAnyShaderFeedingRasterizerSupportedWithoutGSEmulation. Microsoft verbosity is alive and well.)
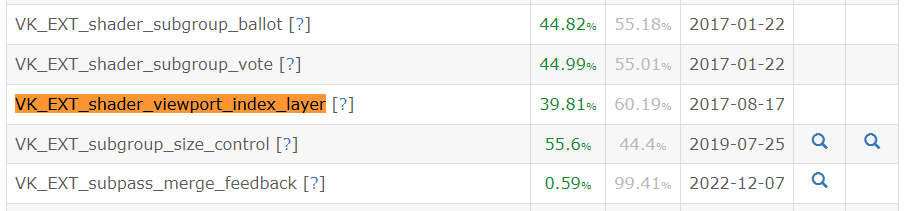
Before we dive into the implementation specifics, let’s briefly go over this feature’s availability in the Vulkan GPU support ecosystem. If your engine is targeting devices with Vulkan 1.2 support and higher, then you can simply query availability and request the core features VkPhysicalDeviceVulkan12Features::shaderOutputLayer and VkPhysicalDeviceVulkan12Features::shaderOutputViewportIndex. The availability of these features across Vulkan 1.2 GPUs is pretty good, hovering around 85% coverage for each, according to the Vulkan Hardware Database.

As a fallback option, or if your engine is targeting support for devices which only allow Vulkan 1.1 or earlier, then you can check for and activate the extension directly, although the general availability of this option is considerably lower for all devices, at only about 40% coverage.
For a modern engine, it would probably be wise to check for the core Vulkan 1.2 features first, falling back to the extension if they are not available, and then falling back again to the naïve approach of just biting the bullet and rendering the scene six times for cubemaps if all else fails. If you so desire, you could also insert the potential usage of geometry shaders for this purpose in that chain as well, but your mileage is sure to vary.
Implementation Details
Assuming we’ve got the functionality available to us, let’s get down to brass tacks. I have implemented this technique using the KerosEngine, the C99 custom game engine I am developing for Studio Kerosene, my indie game development company. Shader code will be presented in plain GLSL and CPU code will be presented using the KerosEngine’s rendering API, which essentially serves as a thin wrapper for Vulkan 1.3. All API concepts and function names should correspond fairly directly to raw Vulkan.
Consider the following trivial example scene:

Hey, this looks familiar… Why, it’s the “Point Shadows” demo scene from Joey de Vries’ LearnOpenGL.com! I chose this scene because it is a very simple demonstration of an omnidirectional cubemap shadow mapping technique that the average graphics programmer is likely to be familiar with, even if they did not copy it directly in the process of building their own hobby engine. That’s what I did, anyway. Joey’s implementation happens to use a geometry shader to accomplish rendering the cubemap in a single draw, so if you are curious about how to do this, I’d recommend reading his article if you haven’t already. We’re going to focus on the other two options.
I’m not going to belabor low-level Vulkan concepts, GPU resource creation, or the full application implementation here. I’m assuming you have a solid understanding of graphics programming and with low-level APIs. If you do not, there are a number of great resources out there which you should check out before continuing.
The following C code snippet is taken from my application’s main draw function. It covers both potential methods we would use to render the cubemap depending on the GPU’s feature availability:
if (mMultiLayerShadow)
{
KE_DECLARE_ZERO(RenderingInfo, shadowRenderingInfo);
shadowRenderingInfo.ppColorAttachments = KE_NULLPTR;
shadowRenderingInfo.ppResolveAttachments = KE_NULLPTR;
shadowRenderingInfo.mColorAttachmentCount = 0;
shadowRenderingInfo.pDepthAttachment = pShadowCubeMapView;
shadowRenderingInfo.pLoadStoreActions = &loadStoreActions;
shadowRenderingInfo.mRenderLayerCount = 6;
renderSceneShadowMultiLayer(pCmd, &shadowRenderingInfo,
pShadowMultiLayerCubePipeline, pShadowMultiLayerRoomPipeline,
SHADOW_DIM, SHADOW_DIM);
}
else
{
KE_DECLARE_ZERO(RenderingInfo, shadowRenderingInfo);
shadowRenderingInfo.ppColorAttachments = KE_NULLPTR;
shadowRenderingInfo.ppResolveAttachments = KE_NULLPTR;
shadowRenderingInfo.mColorAttachmentCount = 0;
shadowRenderingInfo.pLoadStoreActions = &loadStoreActions;
shadowRenderingInfo.mRenderLayerCount = 1;
for (u32 face = 0; face < 6; ++face)
{
shadowRenderingInfo.pDepthAttachment = ppShadowCubeMapFaceViews[face];
renderScene(pCmd, &shadowRenderingInfo,
pShadowCubePipeline, pShadowRoomPipeline,
SHADOW_DIM, SHADOW_DIM, face,
KE_FALSE);
}
}The mMultiLayerShadow variable simply represents whether or not we have the aforementioned Vulkan 1.2 core features and/or the extension available to us. If we do, we call the application function renderSceneShadowMultiLayer(), which binds an ImageView and all six layers/faces of its corresponding shadow cubemap as the depth attachment for rendering at once. If we do not, we call the renderScene() function six times, once for each of six ImageViews representing each one of the shadow cube map’s layers/faces. We actually use the same renderScene() function to shade the scene later in the frame, and in this case we simply pass different color and depth attachments as part of RenderingInfo and different graphics pipelines as parameters.
The renderScene() function draws each of the cubes in the scene (including the room) individually using a simple indexed draw call, like so:
gfxCmdDrawIndexed(
pCmd,
pCubeGeom->pMeshDrawArgs[0].mIndexCount,
pCubeGeom->pMeshDrawArgs[0].mFirstIndex,
pCubeGeom->pMeshDrawArgs[0].mFirstVertex
);The way this works is straightforward enough and requires no further explanation. On the other hand, renderSceneShadowMultiLayer() uses an instanced indexed draw call to render each of the cubes, like so:
gfxCmdDrawIndexedInstanced(
pCmd,
pCubeGeom->pMeshDrawArgs[0].mIndexCount,
6, // Instance count.
pCubeGeom->pMeshDrawArgs[0].mFirstIndex,
pCubeGeom->pMeshDrawArgs[0].mFirstVertex,
0 // First instance.
);Drawing six instances of the cube for each one in the scene will allow us divvy up each instance’s vertices to its corresponding cubemap layer in the vertex shader. The vertex shader is the crux of this entire process. It is presented here:
#version 450
#extension GL_ARB_shader_viewport_layer_array : enable
#include "../../../../KerosEngine/Source/Shaders/Common.ksi"
#include "RootSignatures/ShadingPass.ksi"
layout(location = 0) in float3 inPosition;
layout(location = 1) in float3 inNormal;
layout(location = 2) in float2 inTexCoord;
layout(location = 0) out float3 fragPos;
void main()
{
vec4 position = pushConsts.mOmniShadowConsts.mModel * vec4(inPosition, 1.0);
fragPos = position.xyz;
gl_Position = ubo.lightViewProj[gl_InstanceIndex] * position;
gl_Layer = gl_InstanceIndex;
}Notice that we are enabling the GL_ARB_shader_viewport_layer_array extension. This is what allows us to use the gl_Layer built-in output variable in a vertex shader and compile it using glslc. Creating a Vulkan VkShaderModule with a shader that was compiled with this extension enabled is going to require a Vulkan device with the relevant core features and/or extension enabled, so make sure that is done before trying to actually create pipelines! In this case of our application, we simply do not load the shader or graphics pipelines if these features are found not to be available, with our mMultiLayerShadow variable letting our app logic take care of the rest at draw- and unload-time.
Notice also how we are using gl_InstanceIndex. The instanced draw means that the input assembler will create six vertex shader invocations for every individual vertex in the object, so we can use the built-in instance index to do two things:
Select the output cubemap face’s corresponding view-projection matrix dynamically from an array in our uniform block.
Let the graphics pipeline know which of the six bound render target layers we want this particular vertex to be used for during stream-out and eventual rasterization.
From here, the technique is basically done! No change is required for the depth-only fragment shader which would be required here, or any other fragment shader which would be paired with a vertex shader like this, for that matter. In fact, our particular application’s fragment shader is empty. This is an optimization which ensures no unnecessary fragment shader invocations occur to slow the pipeline down. For shadows, we can make do with the raw depth buffer values in shadow testing during scene shading. However, both this and the method one uses to actually perform the shadow test (PCF, random sampling, etc.) are beyond the scope of this article.
Notes
In general, this method should apply to any algorithm which involves cubemap rendering, and is not limited to depth-only passes such as the one demonstrated here. As long as the functionality is supported on your device, this method is very simple, flexible, and expandable to GPU-driven rendering approaches.
Rather than rendering to a shadow cubemap image view, it is also entirely possible to render to a shadow atlas using multiple viewports into the atlas’ two-dimensional image view. The only difference that this use case would involve is writing to the built-in variable gl_ViewportIndex instead of gl_Layer. Furthermore, since the vast majority of Vulkan-conforming GPUs support up to 16 viewports bound at a time, we can actually use this method to expand the instancing to render two cubemaps at once (12 bound viewports instead of just 6) for even greater savings! More information on SDMV shadow atlas rendering can be found in this great Twitter (X?) thread by János Turánszki.
Lastly, it is hopefully obvious that we could have also been doing an additional layer of instancing, since we are technically still drawing each of the five identical cubes in the scene using separate draws. This would involve a single call to gfxCmdDrawIndexedInstanced() with an instance count of 30 in our case, not 6. For the purposes of this article, I am simply focusing on the minimum number of drawn instances that are needed at once to accomplish the technique at hand. Drawing with a multiple-of-six instance count and resolving the now “two-dimensional” gl_InstanceID in the vertex shader to handle both true instances of the cubes and those only required for this technique is left as an exercise for the reader.
Conclusions

In this article, I have presented a simple method to allow rendering to all six faces of a cubemap in a single draw call without the usage of geometry shaders (Single Draw Multiple Viewport). Of course I did not invent this technique, but there didn’t seem to be any articles or implementation write-ups explaining it in detail online, so I decided to fill this gap in the market. I hope you found it useful!
In terms of performance, the fact that this technique relies on good old instanced rendering rather than geometry shader vertex/primitive emission while also cutting down on graphics API calls should provide wins across the board, depending on your specific GPU of course.
In my case, I was able to check the performance using the KerosEngine’s built-in CPU and GPU profilers, pictured above. The portion of the GPU work dedicated to rendering depth-only shadows (denoted by the “Render Shadows” line in the top right) was optimized from ~13-14 microseconds using the naïve six-draw-call method to ~9-10 microseconds using the SDMV method, which is about 30% savings. Since we know no fragment shader invocations are occuring during this pass (denoted by the “0 FSI” string on the “Render Shadows” line, as reported by Vulkan pipeline statistics), we know that any wins in pipeline efficiency come from the instancing and reduction in draw commands.
However, I would still take this specific result with a grain of salt; at this scale, with this scene, and indeed using this GPU (RTX 4090…) the result in speed is near enough to make little practical difference. Still, the result is consistent across runs, so I figured “what the hell, why not include it?” In a perfect world, this should be benchmarked using a more appropriate and representative scene and card, and perhaps I will revisit this later, but alas, this is what I have available to me at the moment. First world problems? I think I’ll leave you with that question to chew on.